
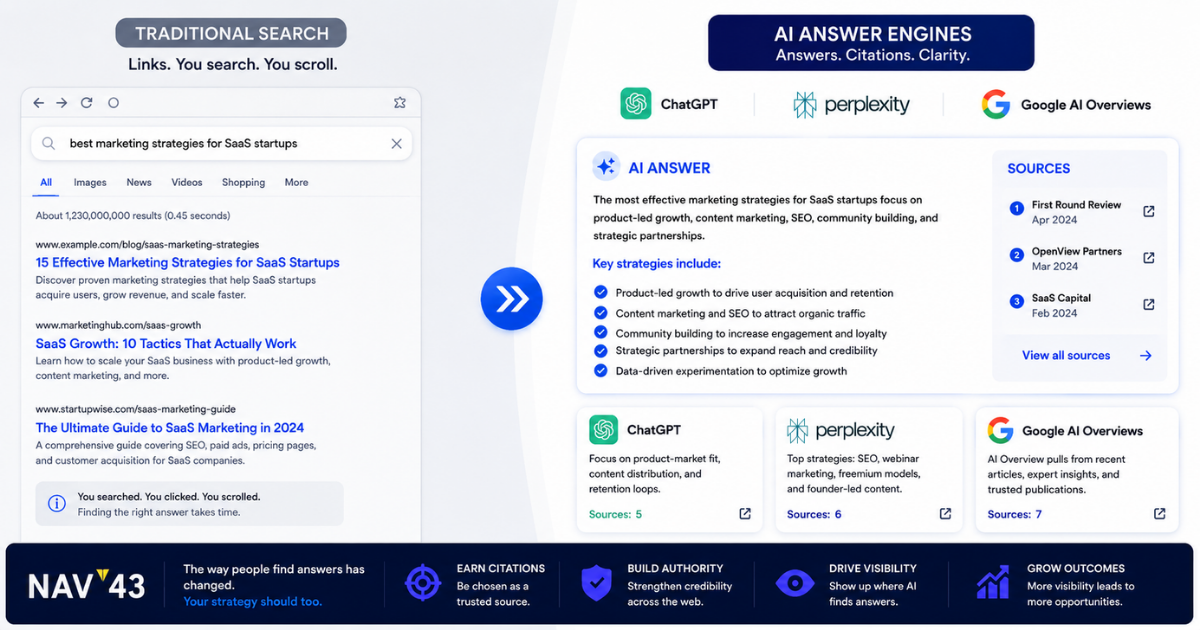
How Answer Engines Choose Sources: 6 Ranking Signals Beyond Blue Links
ChatGPT hit 900 million weekly active users in February 2026, more than double the 400 million from a year earlier (OpenAI/TechCrunch, 2026). Let that sink in. Nearly a billion people are now asking AI systems for answers instead of scrolling through ten blue links.
Here’s the problem: only 11% of domains are cited by both ChatGPT and Perplexity (Digital Bloom, 2025). That means optimizing for one engine doesn’t guarantee visibility in another. The old playbook of building backlinks, ranking for keywords, and collecting clicks no longer applies.
Traditional SEO built authority through link graphs and keyword rankings. But AI engines use fundamentally different signals to decide who gets cited. They’re not returning a list of options. They’re synthesizing a single answer and choosing which sources deserve attribution. Understanding how answer engines choose sources is now the difference between being recommended to millions and being entirely invisible.
This is the practitioner’s guide to understanding exactly how AI engines evaluate and select sources and how to optimize for citation, not just clicks. We’ve been tracking AI citation patterns across client portfolios for 18 months at NAV43, and the signals that matter have shifted dramatically. Gartner predicts traditional search engine volume will drop 25% by 2026 as AI chatbots capture market share (Gartner, 2024). The window to adapt is closing.
Why Backlinks No Longer Predict AI Citations
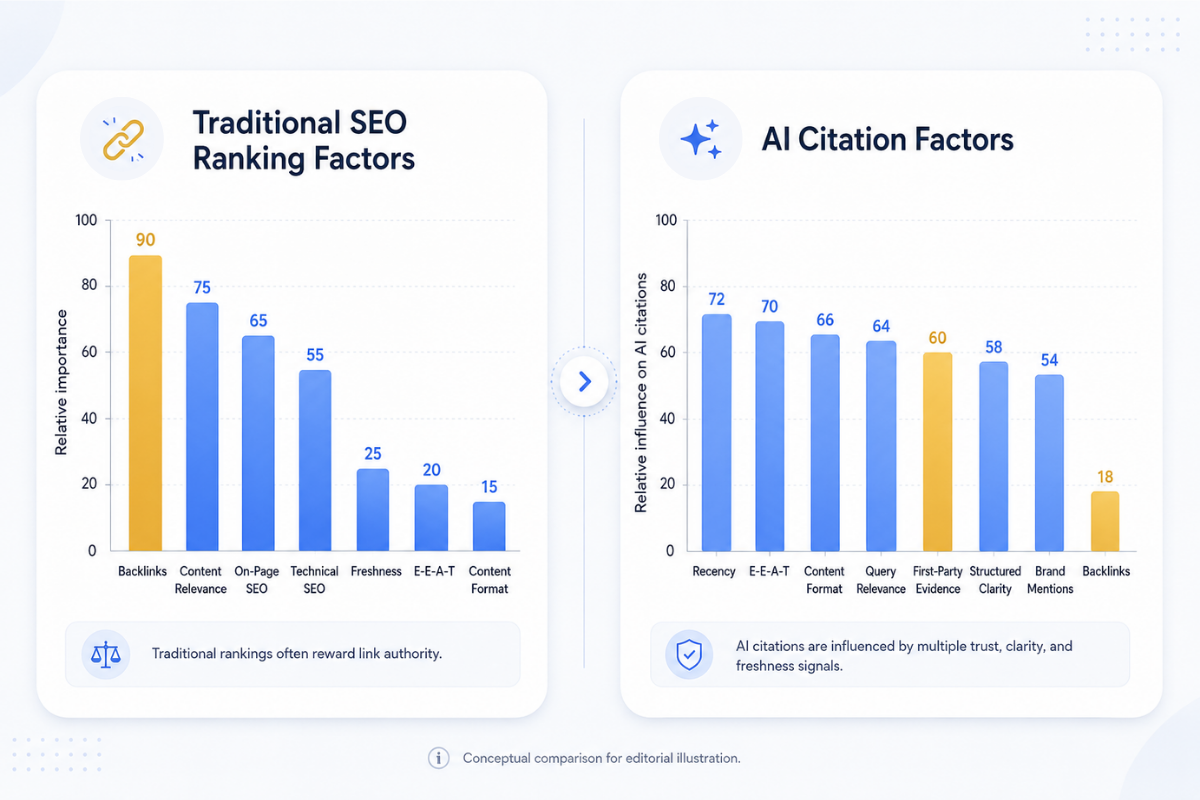
For two decades, SEO operated on a simple premise: links equal votes, votes equal authority, authority equals rankings. Domain Authority scores became the currency of digital credibility. If you wanted to rank, you built backlinks.
That model is crumbling.
Domain Authority correlation with AI citations has dropped to just r=0.18 (Wellows/AI Mode Boost, 2025-2026). For context, that’s barely above random noise. The metric that defined SEO for years now has almost no predictive power for AI visibility.
What replaced it? Entity-based authority. AI systems now correlate brand search volume (0.334 correlation) more strongly than backlinks when deciding which sources to cite. They’re not crawling link graphs. They’re synthesizing information from training data and retrieval systems that prioritize recognized entities.
Think about what this means. An LLM doesn’t see your backlink profile. It sees whether your brand appears consistently across authoritative contexts, including Wikipedia entries, industry publications, knowledge graphs, and verified business directories. It’s measuring recognition, not referrals.
This shift happened because AI systems fundamentally work differently from search engines. Google’s crawler follows links to discover and rank pages. An LLM’s training process ingests massive text corpora and learns which entities are consistently associated with expertise on specific topics. When it retrieves information to answer a query, it weights sources based on learned authority patterns, not link signals.
The data confirms this: 96% of AI Overview citations come from sources with strong E-E-A-T signals (Wellows, 2025-2026). Notice what’s missing from that stat: any mention of Domain Authority thresholds or backlink counts.
The Entity Authority Checklist
Assess your AI-readiness with these five questions:
- Does your brand have a Wikipedia mention (even within another article)?
- Is your Google Knowledge Panel accurate and complete?
- Are you cited as a source in industry publications or research?
- Is your NAP (Name, Address, Phone) data consistent across directories?
- Do branded search queries exist for your company name + topic terms?
If you answered “no” to three or more, entity building should be your priority before content optimization.
Inside the Black Box: How AI Engines Generate and Cite Answers
How AI Systems Break Down Your Question
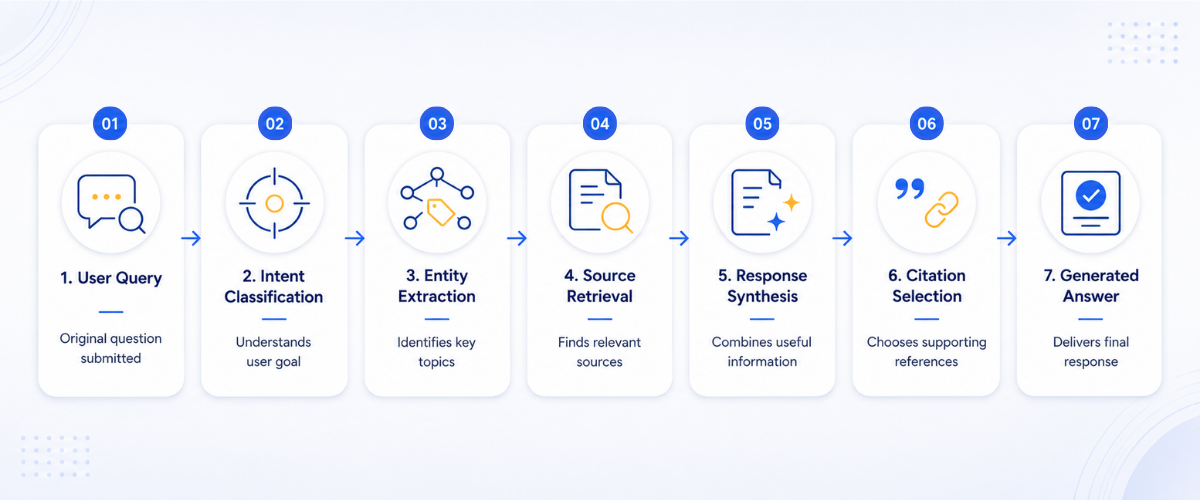
When you ask ChatGPT a complex question like “What’s the best CRM for a 50-person B2B sales team with HubSpot integration?”, you’re not getting a simple database lookup. The system decomposes your query into sub-components, including CRM features, team size requirements, integration capabilities, and B2B use cases, then retrieves relevant content for each.
This process, called retrieval-augmented generation (RAG), works fundamentally differently than traditional search. Google returns ten links and lets you synthesize. AI engines retrieve candidate documents, rank them internally, synthesize a unified answer, and then attribute the sources they drew from.
The difference in query length reveals everything about user expectations. The average ChatGPT prompt is 23 words compared to 3.37 words for traditional Google search (The Growth Memo, 2025). Users are asking nuanced, multi-part questions that require sophisticated retrieval across multiple content sources.
This has profound implications for content strategy. Your page doesn’t need to rank #1 for a single keyword. It needs to be the authoritative answer to a specific facet of a complex question. When an AI system fans out a query into sub-queries, you want your content retrieved for the parts where you have genuine expertise.
What ChatGPT, Perplexity, and Google AI Overviews Each Prioritize

Here’s where most guides fail: they treat “AI search” as a monolithic concept. It isn’t. Each major AI engine has distinct citation behaviors, and understanding the differences is critical for any serious AI SEO strategy.
Google AI Overviews leverage existing search infrastructure. A staggering 76% of citations come from pages already ranking in Google’s top 10, with the median cited URL sitting at position 3 (Ahrefs, 2025). Google AI Overviews essentially repackage top-ranking content into synthesized answers. The top citation sources reveal Google’s preferences: YouTube (23.3%), Wikipedia (18.4%), and Google.com properties (16.4%) dominate (Surfer SEO, 2025). If you’re not ranking organically, AI Overviews won’t save you.
ChatGPT operates differently. It relies on training data plus optional web browsing, meaning its “knowledge” reflects the authoritative publications and structured content that were prominent at training time. Citation behavior varies dramatically based on whether browsing is enabled. Without browsing, it draws from internalized patterns. With browsing, it becomes more like Perplexity, retrieving real-time content but still favoring sources it recognizes as authoritative from training.
Perplexity is the most citation-forward of the major engines. It explicitly sources every claim, retrieves content in real-time, and heavily weights recent, well-structured content with clear attribution. Perplexity essentially operates like a research assistant that shows its work.
| Factor | Google AI Overviews | ChatGPT | Perplexity |
|---|---|---|---|
| Primary citation source | Top 10 ranking pages | Training data + browsing | Real-time web retrieval |
| Freshness sensitivity | High | Moderate | Very high |
| Citation transparency | Partial | Variable | High |
| Video content preference | Strong (YouTube) | Moderate | Moderate |
| Structured data impact | High | Moderate | High |
The 11% domain overlap between ChatGPT and Perplexity (Digital Bloom, 2025) tells you everything. Optimizing for one doesn’t automatically transfer to the other. You need platform-specific approaches.
The New Citation Hierarchy: 6 Signals AI Engines Prioritize
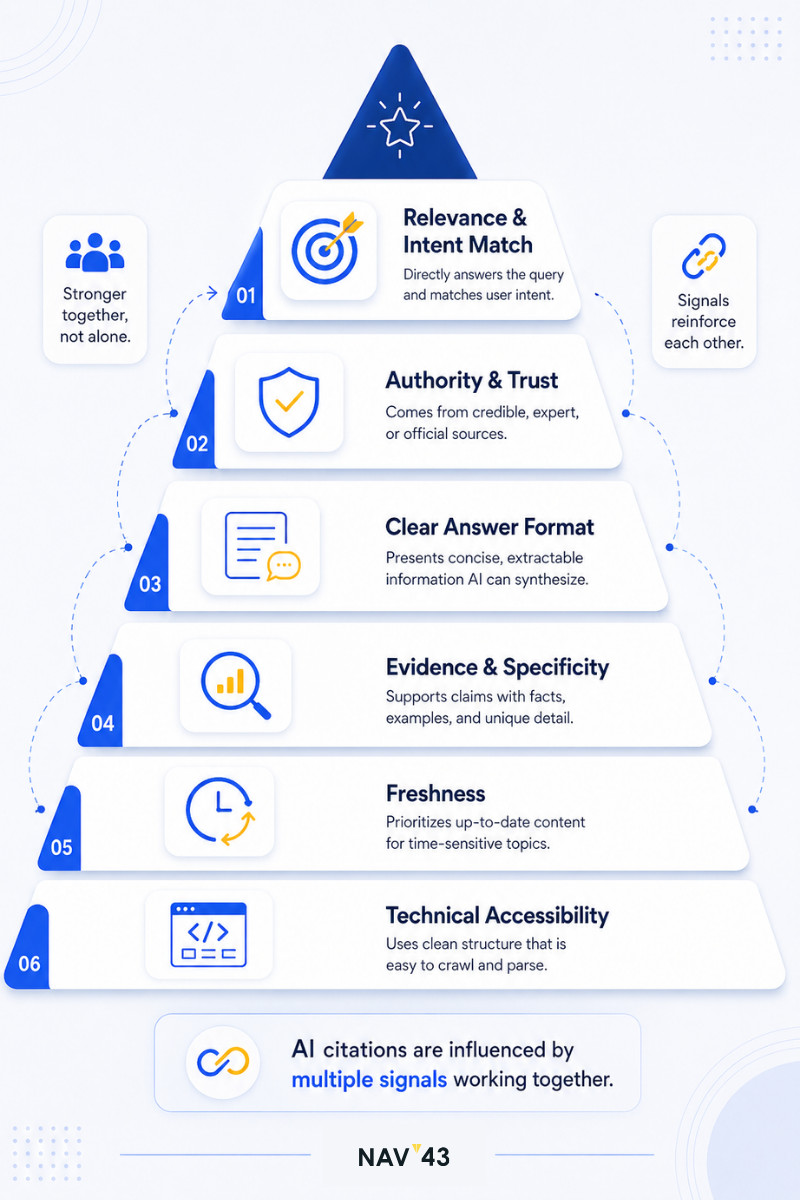
Experience, Expertise, Authority, Trust or Exclusion
E-E-A-T isn’t a ranking boost in AI systems. It’s a binary filter. Without it, you’re not considered at all.
Think of it like a bouncer at an exclusive venue. You can have the best content in the world, but if you don’t meet the threshold requirements for expertise signals, you’re not getting through the door. The 96% statistic bears repeating: nearly all AI Overview citations come from sources with strong E-E-A-T signals (Wellows, 2025-2026).
How do AI systems detect E-E-A-T? They look for:
- Named authors with verifiable credentials not “Admin” or “Content Team”
- Publication reputation including whether you are cited by other authoritative sources
- Expert quotes and primary research since original data beats synthesized summaries
- Transparent sourcing including whether you cite your claims
- Content depth since surface-level overviews signal low expertise
The practical implication is clear. Before optimizing content structure or adding schema markup, audit your E-E-A-T foundation. Author pages with credentials, expert contributor quotes, original research, and a clear sourcing methodology are no longer nice-to-haves. They’re table stakes for AI-ready content.
The 13-Week Rule: Why Recency Dominates
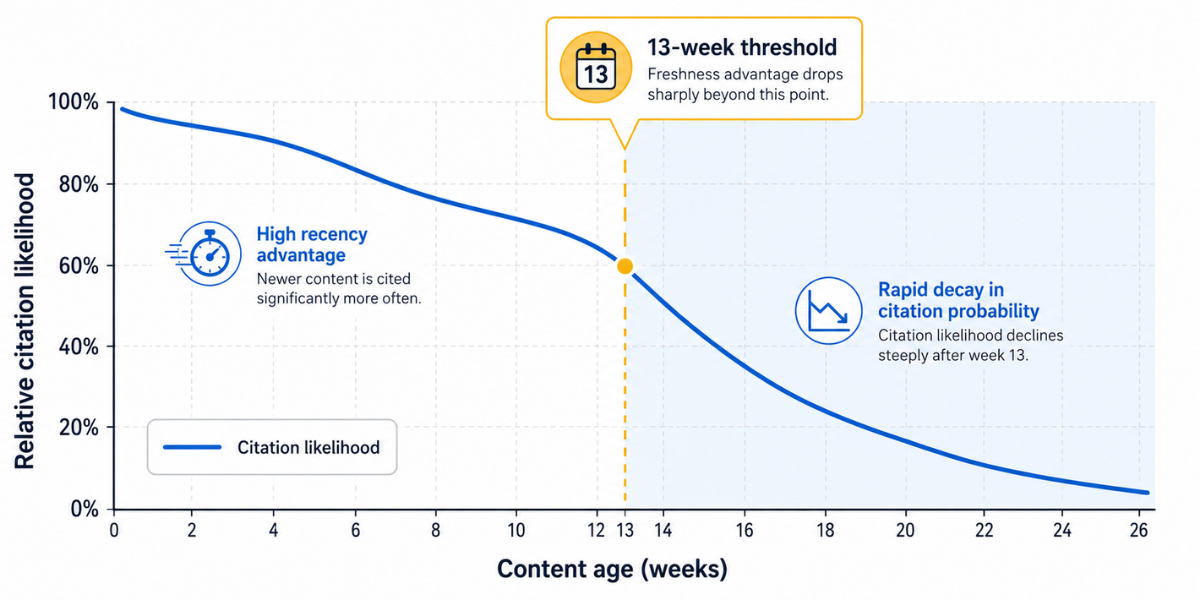
Half of all content cited in AI answers is less than 13 weeks old (Digital Agency Network, 2025-2026). Let that number shape your content calendar.
AI systems are designed to provide current information. When they retrieve candidate documents, recency is a strong signal for relevance, especially for queries with time-sensitive components. Stale content signals potential inaccuracy, and inaccuracy is the cardinal sin for systems trying to provide definitive answers.
The practical guidance is straightforward:
- Update cornerstone content quarterly at a minimum by refreshing statistics, adding new developments, and revising recommendations
- Add “last updated” timestamps to make freshness machine-readable
- Refresh statistics annually since a 2023 stat in 2026 is a citation liability
- Distinguish time-sensitive from evergreen since freshness matters more for “best project management tools 2026” than for “what is project management.”
This doesn’t mean churning out new content daily. It means maintaining living documents. Your pillar pages should evolve with the landscape. Every time a major development occurs in your space, that’s a signal to refresh relevant content.
Why Static HTML with Schema Wins
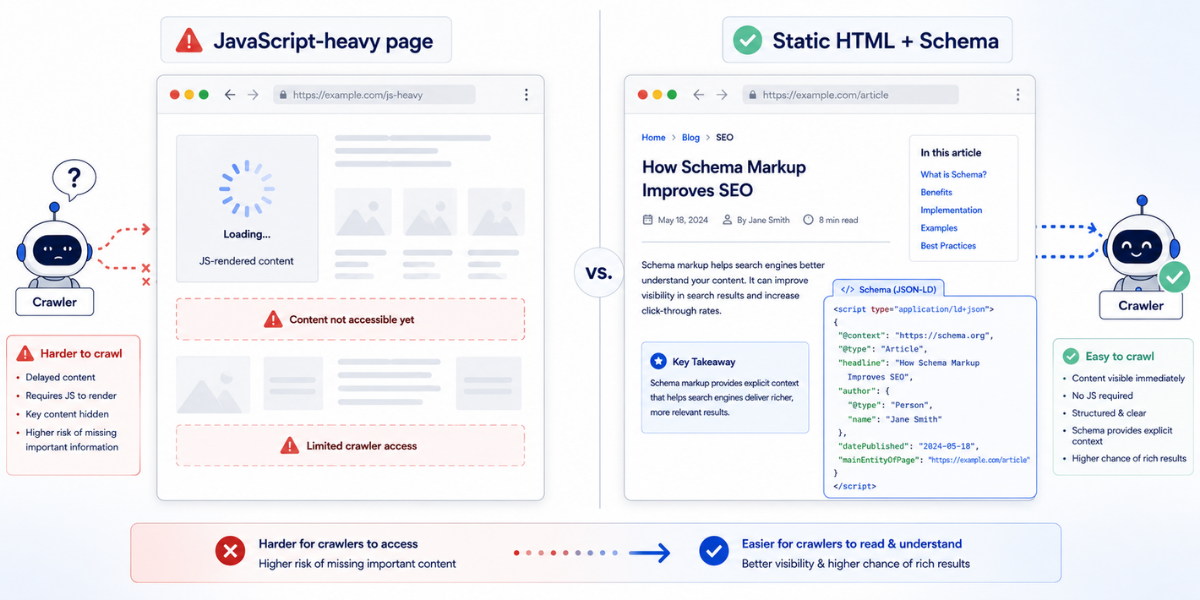
Here’s a technical reality most marketers miss: static HTML with schema achieves 94% AI parsing success versus 23% for JavaScript-rendered content without schema (Erlin Data, 2026). That’s a 4x difference in whether AI systems can even extract your content.
AI retrieval systems struggle with JavaScript-heavy pages. They can’t execute client-side rendering the way browsers do. Clean HTML with semantic markup is dramatically easier to parse and extract. When you combine that with structured data, you’re essentially providing machine-readable context that helps AI systems understand exactly what your content is about.
Schema Markup Priority List for AI Visibility
- FAQPage schema for question-based content, which directly maps to how users query AI
- HowTo schema for instructional content with step-by-step processes AI can extract
- Article schema with author and dateModified to establish freshness and attribution
- Organization schema with sameAs links to reinforce entity identity across platforms
- Product schema with reviews and pricing, essential for e-commerce AI visibility
The emerging llm.txt standard deserves attention, too. Think of it as robots.txt for AI crawlers, a file that tells AI systems what content to prioritize and how to interpret your site structure. It’s not universally adopted yet, but forward-thinking technical SEO teams are already implementing it.
The Quotable Answer Format
AI systems extract concise answers. Your content must provide them upfront, not buried in paragraph seven.
The data is compelling: adding statistics increases AI visibility by 22%, while using quotations boosts visibility by 37% (Princeton GEO Research, 2024-2025). When you combine these tactics, Princeton research shows Generative Engine Optimization can boost content visibility by up to 40% in AI search results (Princeton/KDD 2024).
The ideal structure for AI citation follows this pattern:
- Question as H2 to state the query explicitly
- Direct answer in 2-3 sentences that is quotable, self-contained, and definitive
- Supporting evidence, including statistics, expert citations, and examples
- Expanded explanation for additional context for readers who want depth
Traditional SEO content often saved the conclusion for the end. Answer-first content inverts this. The synthesis should come immediately, with evidence and elaboration following. Think about how AI systems work: they’re looking for extractable answers, not narrative journeys.
This is a fundamental shift in content structure for AI visibility. Your content needs to be quotable in fragments, not just valuable as a whole.
Comprehensive Coverage Beats Keyword Targeting
AI systems understand topics, not just keywords. They evaluate whether content comprehensively addresses a subject, including all its facets, implications, and related concepts.
This is semantic search in practice. You can’t rank for “answer engine optimization” without also covering E-E-A-T, structured data, content freshness, entity authority, and measurement frameworks. AI systems assess topical depth, not keyword density.
The “topical authority” model works like this: covering all aspects of a topic, including related subtopics, common questions, edge cases, and adjacent concepts, signals expertise more strongly than a narrow, keyword-focused piece.
Practical implementation:
- Build topic clusters with pillar pages supported by detailed subtopic content
- Address related questions by considering what else someone asking this would want to know
- Include definitions and don’t assume AI systems or users know every term
- Cover the “why” alongside the “how” since conceptual understanding signals expertise
This is why thin content fails in AI systems. A 500-word overview can’t demonstrate the kind of comprehensive expertise that earns citations.
Your Brand Must Be Recognizable Everywhere
AI systems verify information across sources. Inconsistent data reduces trust, and trust determines citation.
Entity consistency means your company name, founder names, address, founding date, product names, and key claims align across every platform where you appear. When an AI system encounters conflicting information about your brand, it has no way to determine which version is accurate. The default response is reduced confidence in all versions.
Consistency checkpoints include:
- Company name spelled identically across all platforms
- Founder and leadership names with consistent formatting
- Address and contact information matching exactly
- Product names and descriptions aligned
- Key claims, including founding date, employee count, and service offerings, were verified
Wikipedia and knowledge graphs matter enormously here. These are reference sources for AI verification. If your Wikipedia entry or the entries that mention you conflict with your website, that’s a citation liability.
Here’s a stat that should shape your video strategy: YouTube receives 200x more AI citations than any other video platform (Surfer SEO, 2025). Video content builds entity recognition across different modalities, reinforcing your brand’s presence in AI training data and retrieval systems.
Tactical Playbooks by AI Engine
Google AI Overviews: Leverage Your Existing Rankings
The key insight for Google AI Overviews is simple: 76% of citations come from pages already ranking in the top 10 (Ahrefs, 2025). Traditional SEO still matters here. It’s the entry ticket.
AI Overviews expanded dramatically, going from appearing in just 6.49% of searches in January 2025 to over 50% of all queries by October 2025 (Digital Bloom/Semrush, 2025). That’s a fundamental shift in how Google displays results, but the underlying citation logic favors established ranking signals.
Your tactical focus:
- Optimize for featured snippets since these often become AI Overview citations
- Implement FAQ schema since question-answer formats map directly to AI extraction
- Ensure fast, clean rendering since technical SEO is foundational
- Add answer-first formatting so that if you already rank, your content is quotable
If you’re ranking in positions 1-10, the opportunity is enhanced. Add structured data, format for extraction, and ensure E-E-A-T signals are prominent. You’re already in the consideration set.
If you’re not ranking organically, AI Overviews won’t circumvent that problem. You need to build traditional SEO foundations while simultaneously preparing content for AI extraction.
ChatGPT and Copilot: Build Training Data Authority
ChatGPT relies heavily on training data. Getting cited requires being an authoritative source before the model’s knowledge cutoff, which means your content needs to be prominent in the right places before training occurs.
This sounds discouraging for new content, but there’s a crucial nuance: when browsing is enabled, ChatGPT becomes more dynamic. Freshness and structure matter more. The balance shifts toward Perplexity-like behavior.
Your tactical focus:
- Earn mentions in high-authority publications since these shape training data
- Publish primary research that others cite to become a source that sources reference
- Maintain consistent entity information since conflicting data reduces training-time authority
- Structure content for extraction since even in browsing mode, quotable formats win
Think of it this way: you want to build the kind of authoritative footprint that would get you cited in a Wikipedia article. That’s the standard implicit in ChatGPT’s training process.
Perplexity: Win the Real-Time Retrieval Game
Perplexity does real-time web retrieval and explicitly cites sources. It’s the most citation-transparent engine. If you want to understand what AI citation looks like at its most visible, study Perplexity’s behavior.
The freshness premium is severe here. Perplexity heavily weights recency, making your content calendar a competitive weapon. This is where consistent publishing pays the highest dividends.
Your tactical focus:
- Publish frequently to maintain a steady stream of fresh, relevant content
- Use clear sourcing in your own content since well-cited content gets cited
- Structure for easy extraction using headers, bullets, and concise paragraphs
- Target emerging topics quickly since being first with quality content matters
Treat Perplexity like a news-hungry editor who wants well-sourced, current content. If your piece is three months old and a competitor published something similar last week, Perplexity will likely favor the fresher source.
Tracking What Matters: New KPIs for the AI Era
Beyond Position Tracking: AI Visibility KPIs
Here’s the uncomfortable truth: the industry lacks standardized frameworks for AI citation tracking. Traditional rank-tracking tools measure position on a SERP, which is increasingly not the primary answer-delivery mechanism.
We’re working in a transitional period where measurement methodologies are still evolving. But several emerging KPIs are proving useful for measuring AI visibility.
AI Citation Frequency measures how often your brand or content is cited across AI engines for target queries. This requires systematic query testing, asking AI systems your target questions, and documenting citation patterns over time.
Share of Model tracks your brand’s citation share compared to competitors for a topic cluster. If there are five key queries in your category, what percentage cite you versus competitors?
AI Referral Traffic is direct traffic from AI engines, trackable via UTM parameters and referrer data. This is the bridge metric between citation and business impact.
Citation Quality Score asks whether you are cited as a primary source (the main answer) or a supporting mention (one of several sources). Primary citations drive more brand impact.
The ROI case is strong. AI-referred visitors demonstrate significantly higher value, and HubSpot reported 3x better lead conversion from AEO traffic compared to other sources (HubSpot, 2025-2026). AI-referred traffic jumped 527% year-over-year in the first five months of 2025 (Previsible, 2025). The audience you find through AI is high-intent.
Tools and Methods for AI Citation Tracking
Until standardized tools mature, build a measurement stack that combines manual monitoring with emerging automation.
Manual monitoring remains essential. Regularly query your target keywords in ChatGPT, Perplexity, and Google AI Overviews. Document citation patterns systematically by tracking which queries cite your brand, what specific content gets cited, how citation changes over time, and where competitors get cited instead of you.
Third-party tools are evolving rapidly. Semrush, Ahrefs, and specialized AI visibility platforms are adding citation-tracking features. These aren’t fully mature yet, but they’re worth monitoring. Early adopters who build familiarity with emerging tools will have an advantage as measurement standards become standardized.
GA4 and referrer tracking provide the closest thing to hard metrics. Configure your analytics to segment AI-referred traffic by looking for referrers from openai.com, perplexity.ai, bing.com (Copilot), and google.com (AI Overviews). Track conversion rates for this segment separately. Our experience shows AI-referred visitors often have different intent patterns than traditional search traffic.
Query sampling methodology is critical for tracking the Share of Model. Build a representative sample of 50-100 queries across your topic clusters. Test them monthly across major AI engines. Document citation patterns and calculate your share versus competitors. This is labor-intensive, but it’s currently the most reliable way to measure AI visibility trends.
Common Pitfalls to Avoid
Treating all AI engines identically is a costly mistake. The 11% domain overlap between ChatGPT and Perplexity proves this (Digital Bloom / 2025 AI Visibility Report, 2025). Each engine has distinct citation behaviors, so optimize for each platform’s preferences.
Over-investing in backlinks while ignoring entity authority misallocates your budget. Domain Authority correlation with AI citations is just r=0.18. If you’re still prioritizing link building over entity building, you’re optimizing for yesterday’s signals.
Publishing stale content and expecting citations is a losing strategy. Half of the cited content is less than 13 weeks old. If your cornerstone content hasn’t been updated this quarter, it’s a liability.
Using JavaScript-heavy rendering without schema creates an invisible barrier. The gap is stark: 94% parsing success for static HTML with schema versus 23% for JavaScript without (Erlin Data, 2026). The technical foundation matters.
Burying answers in narrative content costs you citations. AI systems extract concise answers, so lead with the synthesis. Answer-first formatting is non-negotiable.
Ignoring E-E-A-T as a threshold requirement disqualifies you entirely. With 96% of AI Overview citations coming from sources with strong E-E-A-T signals (Wellows / AI Mode Boost, 2025-2026), this isn’t a boost factor. It’s an inclusion filter. No E-E-A-T means no consideration.
Conclusion: Adapt Now or Cede Ground to Competitors Who Do
The shift from ranking to citation is not a future trend. It is the present reality. With ChatGPT at 900 million weekly active users, Google AI Overviews appearing in over 50% of all queries, and Perplexity growing as the research tool of choice for high-intent buyers, the brands that understand how answer engines choose sources are already pulling ahead.
The core lesson from everything covered in this guide is that AI engines are not simply faster search engines. They are synthesis machines that, based on a distinct set of signals, decide which sources deserve to be quoted and which are ignored entirely. Domain Authority and backlink counts are nearly irrelevant. Entity recognition, E-E-A-T signals, content structure, freshness, and technical accessibility are what determine whether you make the cut.
This matters most because the traffic being redirected through AI answers is the highest-converting traffic available. AI-referred visitors convert at 4-5x the rate of traditional organic search visitors. HubSpot data shows a 3x higher lead conversion rate from AEO traffic. The audience discovering brands through AI citations is actively seeking answers, not passively browsing. Earning citations means earning buyers.
The window to build this foundation is open now, but it is narrowing. Gartner’s 25% decline in traditional search volume is materializing. Brands that continue optimizing exclusively for traditional SERPs while ignoring AI citation signals will see compounding losses as AI search captures more of the market. The good news is that the actions required to earn AI citations, including building entity authority, strengthening E-E-A-T signals, structuring content for extraction, and maintaining technical accessibility, also strengthen your traditional SEO. This is not a choice between the old playbook and the new one. It is an upgrade.
Start with the audits outlined above. Test your visibility across ChatGPT, Perplexity, and Google AI Overviews today. Identify where competitors are being cited instead of you. Then work systematically through the six signals covered in this guide, beginning with whichever represents your biggest gap.
If you want an expert assessment of your current AI visibility and a roadmap for capturing citation share in your category, get a free growth plan from the NAV43 team. We’ve been tracking these citation patterns across client portfolios since the beginning of the AI search era.
The rules have changed. The question is whether you’ll change with them.
