
AI Crawlers vs Search Crawlers: What Technical SEO Teams Need to Know in 2026
Here’s a stat that should stop you mid-scroll: AI crawlers now make 3.6x more requests than traditional search crawlers (Search Engine Journal/Alli AI, 2026). Let that sink in. The bots scraping your site aren’t primarily Googlebot anymore. Instead, they’re GPTBot, ClaudeBot, PerplexityBot, and a growing army of AI systems hungry for your content.
But here’s where it gets painful. These crawlers consume your server resources, eat your bandwidth, and send back almost nothing in return. Anthropic’s Claude has a crawl-to-refer ratio of up to 70,900:1 (Cloudflare, 2025). For every 70,900 pages Claude’s bot crawls, it sends approximately one visitor back to your site. Compare that to Google’s ratio of 3:1 to 30:1, and you start to understand the fundamental economics problem facing technical SEO teams in 2026.
By late 2025, Cloudflare’s network was handling approximately 50 billion crawler requests per day from AI bots alone (Cloudflare/Thunderbit, 2025). This isn’t a theoretical concern – it’s infrastructure cost hitting your bottom line right now.
I was reviewing server logs for one of our e-commerce clients last month, and what I found perfectly illustrates the “crawler identity crisis” facing technical SEO teams. They weren’t managing one type of bot anymore. They were managing three distinct categories of AI crawlers with completely different implications for their business: training crawlers that steal intellectual property, retrieval crawlers that enable AI citations, and user-action crawlers that no longer even promise to respect robots.txt.
The stakes couldn’t be higher. According to Bain & Company, 40-60% of B2B buyers now use AI systems for vendor research. Block the wrong crawler to lose visibility into AI-generated recommendations. Allow the wrong crawler, and you’re training your competitor’s AI on your proprietary content.
In this guide, I’ll break down the three AI crawler categories, explain the robots.txt paradox that makes this so complicated, reveal the JavaScript rendering gap most teams miss entirely, and give you a decision framework for strategic crawler management that actually aligns with your business goals. This is the exact framework we use with clients at NAV43, and it’s what separates brands that thrive in the AI search era from those that get left behind.
What Is an AI Crawler? (And Why Technical SEO Teams Should Care)
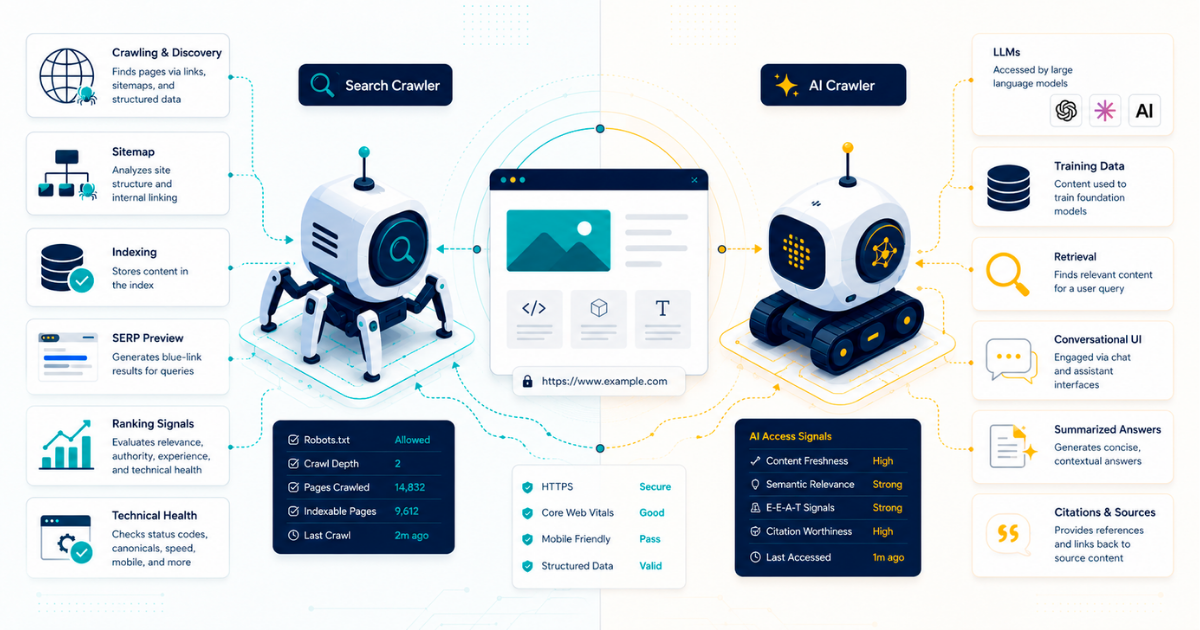
An AI crawler is an automated bot that scans websites to collect content for AI model training, real-time retrieval for AI-generated answers, or user-triggered browsing actions. Unlike traditional search crawlers that index content for search result pages, AI crawlers either feed data into machine learning models or retrieve information to power conversational AI responses.
This distinction matters because it fundamentally changes the value exchange between your website and the systems consuming your content. Traditional search crawlers indexed your pages so users could find you through search results. AI crawlers take your content to answer questions directly, often without ever sending a user to your site.
The growth trajectory is staggering. GPTBot grew 305% in requests from May 2024 to May 2025, jumping from the #9 crawler by volume to #3 (Cloudflare, 2025-2026). User-driven AI bot crawling increased more than 15x in 2025 (Cloudflare Year in Review, 2025). This isn’t a gradual shift, it’s a fundamental restructuring of how content gets discovered and consumed.
For technical SEO teams, this creates several critical concerns:
- Crawl budget competition: AI crawlers may crowd out Googlebot, especially on large sites with crawl budget constraints
- Server load: High-volume AI crawling increases infrastructure costs without corresponding traffic benefits
- Content licensing implications: Your content may be training AI models that compete with your business
- The new “AI visibility” metric: Being cited in AI-generated answers is becoming as important as ranking in search results
This isn’t a theoretical concern. One of our e-commerce clients saw a 40% spike in bot traffic over six months – nearly all of it from AI crawlers that weren’t sending a single referral back. When we analyzed their server logs, we found they were effectively subsidizing the training of AI systems that could eventually recommend their competitors.
The Three Categories of AI Crawlers
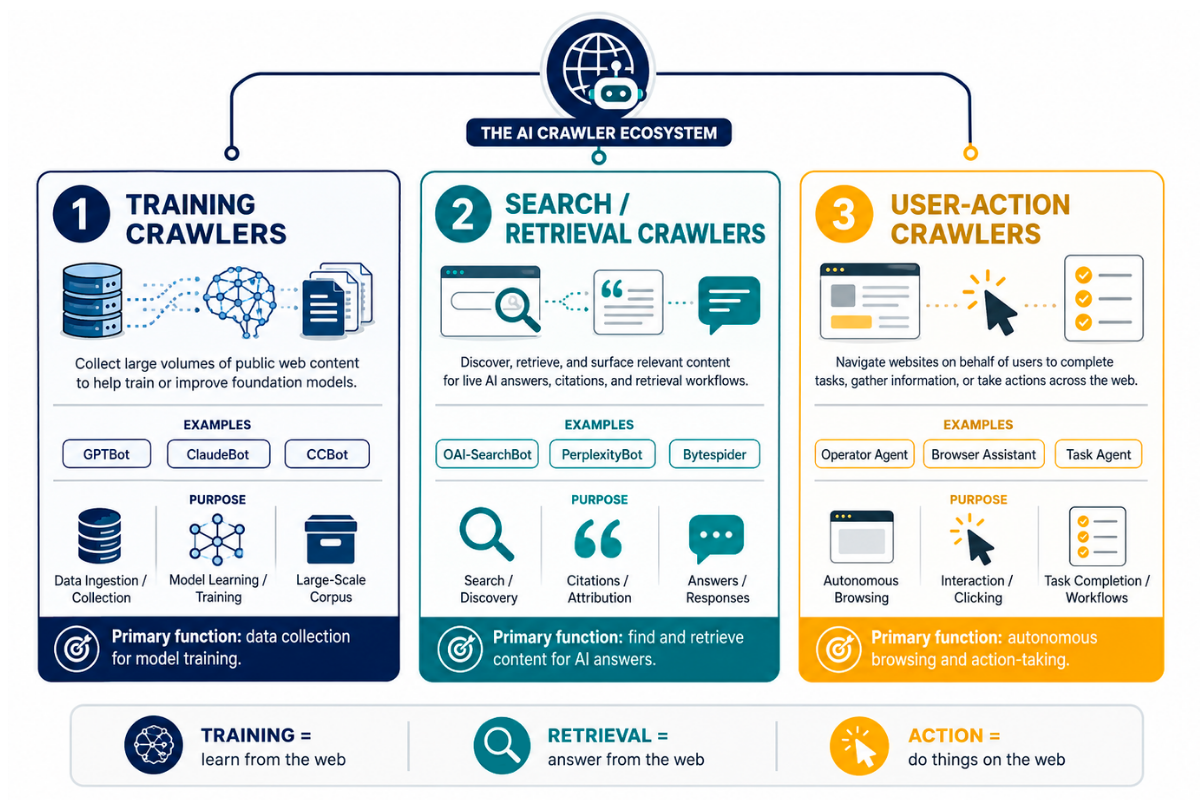
Understanding AI crawlers requires moving beyond the monolithic view that lumps all bots together. At NAV43, we use a classification framework that separates AI crawlers by their primary purpose, because the business implications differ dramatically depending on what each crawler is actually doing with your content.
Category 1: Training Crawlers
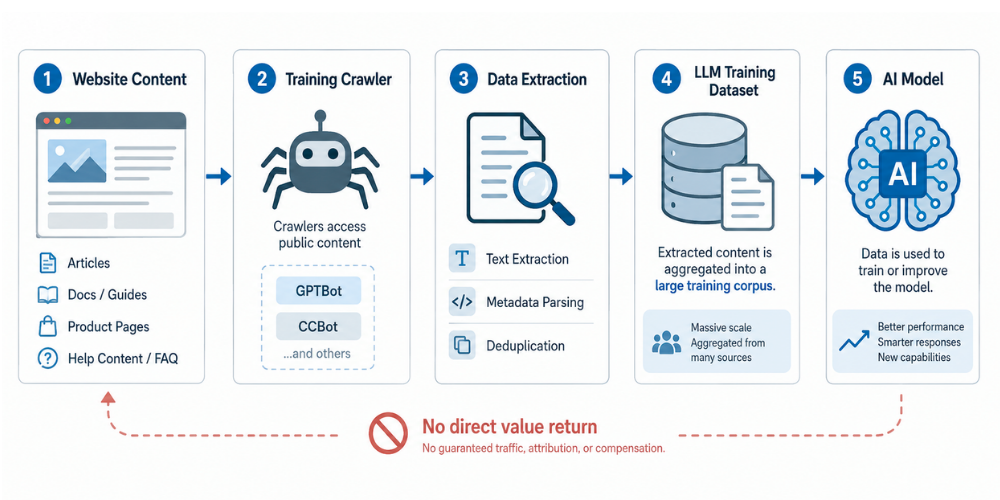
Purpose: Collect content to train foundation models
Key Players:
– GPTBot (OpenAI) – Trains GPT models
– ClaudeBot (Anthropic) – Trains Claude models
– Google-Extended – Trains Google’s Gemini AI
– CCBot (Common Crawl) – Feeds open training datasets
– Bytespider (ByteDance) – Trains TikTok’s AI systems
Business Implication: Your content becomes training data for AI systems, including tools your competitors might use. Once your content trains a model, there’s no retrieval or attribution. It’s simply absorbed into the model’s knowledge base.
Category 2: Search/Retrieval Crawlers
Purpose: Real-time content retrieval for AI-generated answers
Key Players:
– OAI-SearchBot (OpenAI) – Fetches content for ChatGPT’s search features
– PerplexityBot (Perplexity) – Powers Perplexity’s answer engine
– Amazonbot – Retrieves content for Alexa and Amazon’s AI features
Business Implication: Blocking these may reduce your visibility in AI-generated citations. However, allowing them means your content powers answers that may not send users to your site.
Category 3: User-Action Crawlers
Purpose: Triggered by live user queries – someone asks ChatGPT a question, and the bot fetches current information
Key Players:
– ChatGPT-User (OpenAI) – Activated when users ask ChatGPT to browse the web
– Applebot – Powers Siri integration and Apple Intelligence features
Business Implication: Critical policy change in December 2025: ChatGPT-User no longer commits to honoring robots.txt directives. This means your traditional blocking approach may be ineffective against the fastest-growing category of AI crawlers.
AI Crawler Reference Table
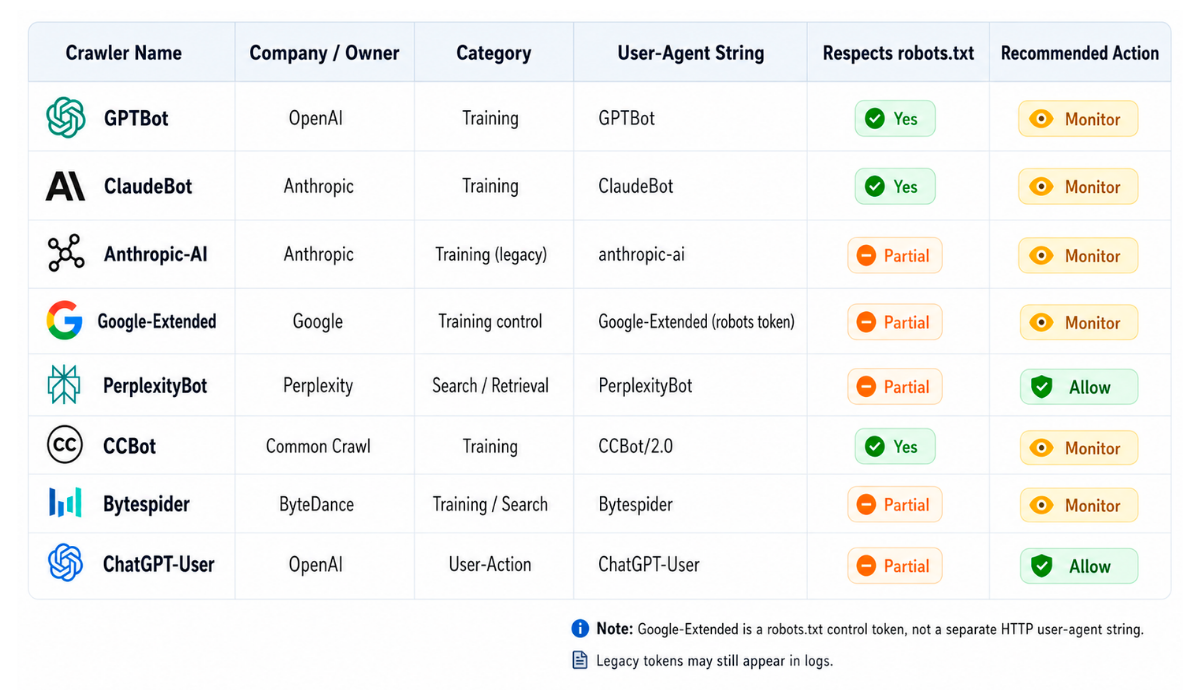
| Crawler | Operator | Category | Respects robots.txt |
|---|---|---|---|
| GPTBot | OpenAI | Training | Yes |
| OAI-SearchBot | OpenAI | Retrieval | Yes |
| ChatGPT-User | OpenAI | User-Action | No longer guaranteed |
| ClaudeBot | Anthropic | Training | Yes |
| PerplexityBot | Perplexity | Retrieval | Yes |
| Google-Extended | Training | Yes | |
| Amazonbot | Amazon | Retrieval | Yes |
| Bytespider | ByteDance | Training | Inconsistent |
| CCBot | Common Crawl | Training | Yes |
| Applebot | Apple | User-Action | Yes |
AI Crawlers vs Traditional Search Crawlers: The Core Differences
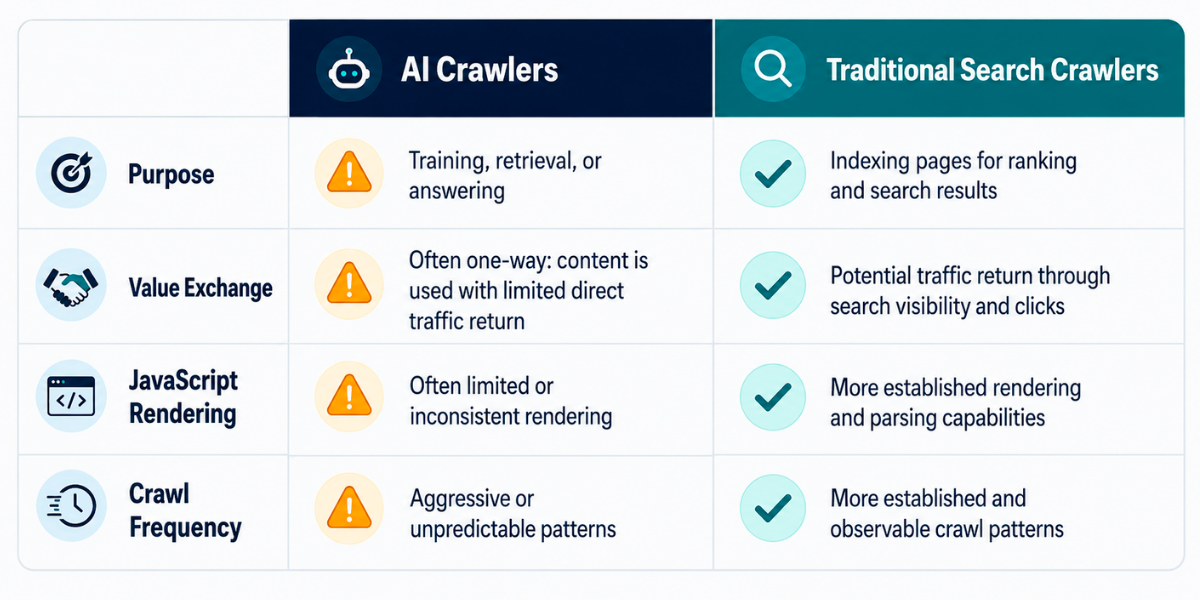
The gap between AI crawlers and traditional search crawlers goes far beyond their stated purpose. Understanding these differences is essential for any technical SEO strategy that accounts for the AI search era.
Difference 1: Purpose
Traditional crawlers like Googlebot and Bingbot index content for search rankings. When they crawl your page, they’re building a search index that helps users find you through search queries.
AI crawlers serve two fundamentally different purposes: they either train models (by extracting your content to improve AI capabilities) or retrieve content for generative answers (by pulling your information to answer user questions directly within AI interfaces).
Difference 2: Value Exchange
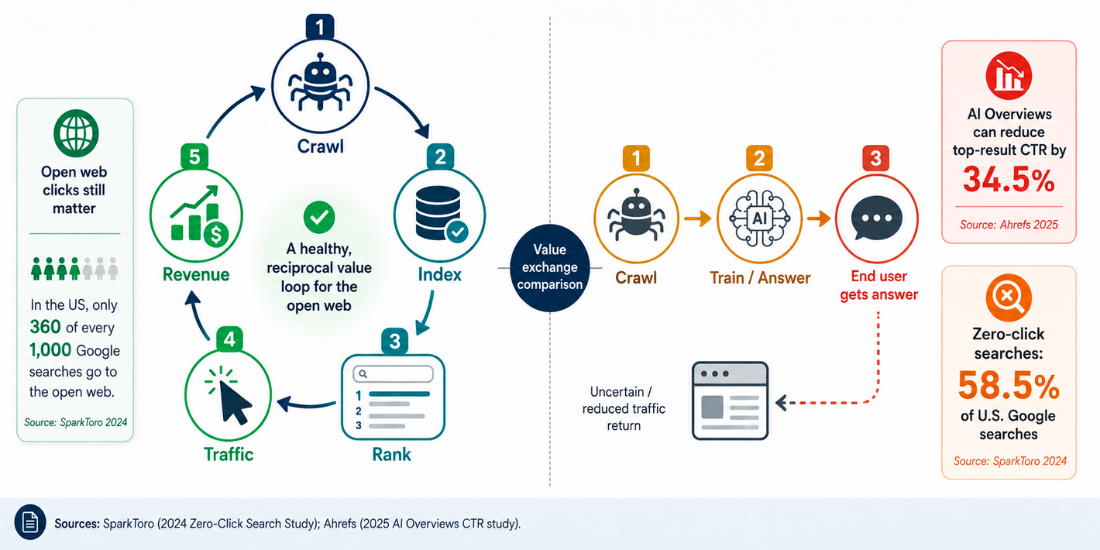
This is where the economics get brutal. Google’s crawl-to-refer ratio is 3:1 to 30:1, meaning for every 3-30 pages crawled, Google sends back 1 visitor (Cloudflare, 2025). That’s a reasonable value exchange.
Anthropic’s Claude has a crawl-to-refer ratio of up to 70,900:1 (Cloudflare, 2025). For practical purposes, Claude takes your content and sends nothing back. PerplexityBot and other AI crawlers fall somewhere in between, but the pattern is clear: AI systems take more and give less.
Difference 3: JavaScript Rendering
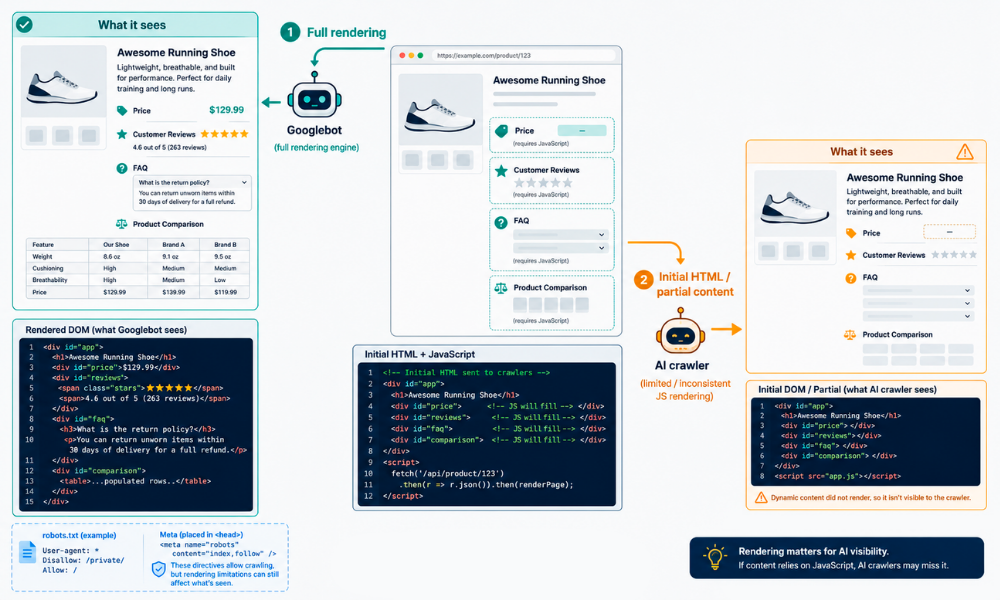
Googlebot executes JavaScript. It can see content loaded by React, Angular, Vue, and other client-side frameworks. This has been the case for years, and most technical SEO teams have adapted accordingly.
AI crawlers – GPTBot, ClaudeBot, PerplexityBot – do not execute JavaScript. They see only the raw HTML served by your server. If your product information, pricing, or key content loads via JavaScript, AI crawlers cannot see it.
Difference 4: Crawl Frequency
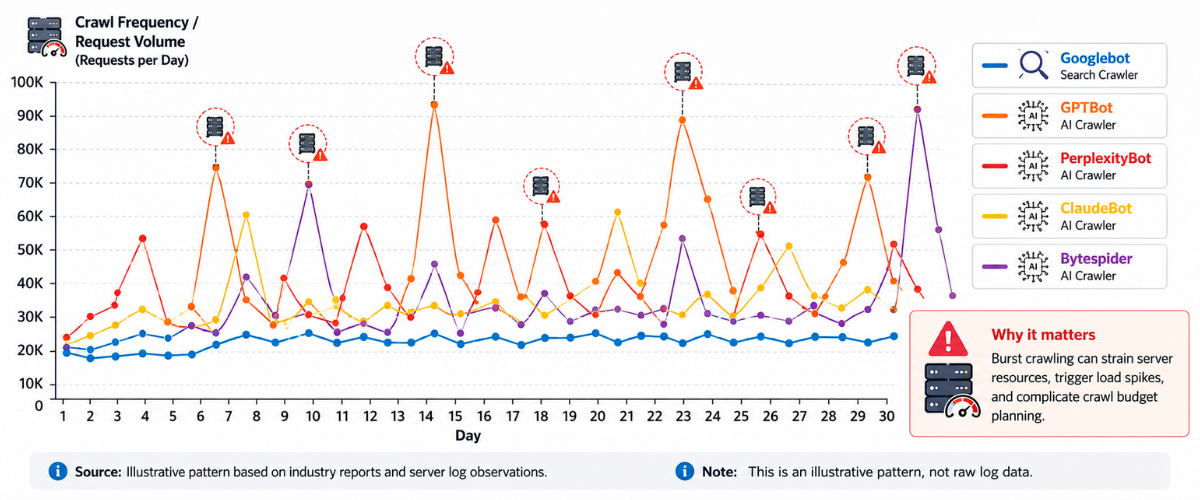
AI crawlers make 3.6x more requests than traditional search crawlers (Search Engine Journal/Alli AI, 2026), but their crawl patterns are less predictable. They don’t follow the same recrawl schedules as traditional search engines.
Difference 5: Robots.txt Compliance
Traditional search crawlers reliably honor robots.txt directives. This has been the gentleman’s agreement of the web for decades.
AI crawler compliance varies and is actively changing. The December 2025 policy shift, where ChatGPT-User no longer commits to honoring robots.txt, represents a fundamental erosion of publisher control.
Difference 6: Traffic Distribution
According to Cloudflare, 80% of AI crawling traffic is for model training, 18% for search/retrieval, and 2% for user actions (Cloudflare, 2025). This means the vast majority of AI crawler traffic isn’t sending anything back – it’s purely extractive.
Comparison Table: Traditional Search Crawlers vs AI Crawlers
| Dimension | Traditional Search Crawlers | AI Crawlers |
|---|---|---|
| Primary Purpose | Index for search results | Train models or generate answers |
| JavaScript Rendering | Yes (Googlebot, Bingbot) | No (most AI crawlers) |
| Crawl-to-Refer Ratio | 3:1 to 30:1 | 70,900:1 (Claude) to ~100:1 (ChatGPT) |
| Request Volume | Baseline | 3.6x higher |
| Robots.txt Compliance | Reliable | Variable, eroding |
| Value Exchange | Traffic in exchange for crawling | Minimal to none |
| Blocking Implications | Lose search visibility | May still get cited; may lose AI visibility |
The JavaScript Visibility Gap
Here’s a critical technical distinction that separates traditional search visibility from AI visibility: sites relying on client-side JavaScript rendering are invisible to AI systems while remaining visible to Google.
Googlebot has executed JavaScript since 2019. If your React or Vue app loads product information dynamically, Googlebot eventually sees it. But GPTBot, ClaudeBot, and PerplexityBot do not render JavaScript. They see only what’s in your initial HTML response.
If your product pages, pricing, or key content loads via JavaScript, AI crawlers can’t see it. Period.
This creates a dangerous blind spot. You might rank well in traditional search while being completely absent from AI-generated answers simply because your content is trapped behind JavaScript.
Recommended Technical Fixes:
- Server-Side Rendering (SSR): Render critical content on the server before sending to the client
- Prerendering: Generate static HTML snapshots for bot requests
- Static Site Generation: Build fully static pages for content that doesn’t change frequently
- Critical Content in Initial HTML: Ensure headlines, product names, pricing, and key information appear in the raw HTML
We’ve seen this repeatedly in client audits – sites ranking well in traditional search but completely absent from AI-generated answers because their content is trapped behind JavaScript. If you’re running a JavaScript-heavy application, this should be at the top of your technical SEO audit checklist.
Is ChatGPT a Web Crawler? Understanding OpenAI’s Bot Ecosystem
Let me clear up a common misconception: ChatGPT itself is not a web crawler. ChatGPT is an AI chatbot. However, OpenAI operates multiple crawlers that serve different purposes within the ChatGPT ecosystem.
OpenAI’s Crawler Ecosystem
GPTBot: This is OpenAI’s training crawler. It collects content to improve GPT models. When you block GPTBot, you’re preventing your content from training future versions of GPT.
OAI-SearchBot: This is OpenAI’s retrieval crawler. It fetches content for ChatGPT’s search features – when a user asks ChatGPT a question that requires current information, OAI-SearchBot may retrieve your content to inform the answer.
ChatGPT-User: This is triggered when a user explicitly asks ChatGPT to browse the web. Someone types “go to [website] and tell me about…” and ChatGPT-User crawls that URL.
The December 2025 Policy Change
Here’s the critical update that changes everything: In December 2025, OpenAI announced that ChatGPT-User may no longer honor robots.txt directives. Additionally, OAI-SearchBot and GPTBot now share crawl data.
This creates several implications:
- Blocking GPTBot no longer guarantees your content won’t be used for training if OAI-SearchBot can access it
- Traditional robots.txt blocking may be ineffective against user-triggered browsing
- The lines between “training” and “retrieval” are blurring within OpenAI’s ecosystem
You can technically still block training (GPTBot) while allowing retrieval (OAI-SearchBot) to maintain AI citation visibility, but the boundaries are eroding.
AI Referral Traffic Reality
Despite the complexity, AI referral traffic is growing. According to Conductor’s 2026 benchmarks, AI referral traffic accounts for 1.08% of all website traffic and is growing roughly 1% month over month. ChatGPT drives 87.4% of that traffic (Conductor, 2026).
This might seem small, but consider: if Gartner’s prediction that traditional search engine volume will drop 25% by 2026 holds true, that 1.08% becomes increasingly important in a shrinking pie. Understanding how to optimize for AI visibility is becoming essential, which is exactly why we’ve built comprehensive guides on how to create AI-ready content.
The Robots.txt Paradox: Why Blocking AI Crawlers Isn’t a Clean Answer
Here’s the paradox that keeps technical SEO teams up at night: blocking AI crawlers doesn’t necessarily prevent AI citations, but NOT blocking them costs you infrastructure resources and feeds your data to competitors’ training datasets.
The data is clear but conflicting:
- 79% of top news sites block AI training bots via robots.txt; 71% also block AI retrieval bots (BuzzStream, 2025)
- Publishers blocking AI crawlers experienced a total traffic decline of 23.1% in monthly visits (Rutgers Business School & Wharton School, 2025)
- Yet 75% of blocked sites still get cited in AI-generated answers through cached data, third-party sources, and partnerships (Conductor, 2025)
The Dual-Purpose Crawler Problem
Google makes this even more complicated. Google uses Googlebot for both search indexing AND AI training (for Gemini). If you block Google-Extended to prevent AI training, you don’t affect search indexing, as Google intentionally separated these. But the precedent is concerning: dual-purpose crawlers force impossible choices.
The Business Decision Tree
Block Training Crawlers (GPTBot, Google-Extended, ClaudeBot):
– Protects intellectual property and proprietary content
– Reduces infrastructure load from high-volume crawling
– Prevents your content from being trained by competitor tools
– Risk: May reduce long-term influence on the AI model knowledge
Allow Retrieval Crawlers (OAI-SearchBot, PerplexityBot):
– Maintains visibility in AI-generated answers
– Enables citation in conversational AI responses
– Trade-off: Training/retrieval boundaries are blurring
– Requires acceptance that some content may be used beyond retrieval
Allow User-Action Crawlers (ChatGPT-User):
– Captures real-time visibility when users ask AI systems questions
– Positions you for voice and conversational search
– Challenge: December 2025 policy change means you may not have a choice anyway
There’s no universally correct answer. The right configuration depends on your content’s competitive value, your infrastructure capacity, and your AI visibility goals.
Robots.txt Implementation Guide: Training vs Retrieval vs User-Action
Here’s where strategy becomes implementation. Based on your business decision, here are the exact robots.txt configurations for each scenario.
Scenario A: Block All AI Crawlers
Use this if you prioritize intellectual property protection over AI visibility.
# Block all major AI crawlers
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
Scenario B: Block Training, Allow Retrieval
Use this if you want AI citation visibility while protecting against model training.
# Block training crawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
# Allow retrieval crawlers for AI citation visibility
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Amazonbot
Allow: /
# Note: ChatGPT-User no longer guaranteed to honor directives
User-agent: ChatGPT-User
Allow: /
Scenario C: Allow All AI Crawlers
Use this if you want maximum AI exposure and aren’t concerned about training implications.
# Allow all AI crawlers
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Amazonbot
Allow: /
User-agent: Bytespider
Allow: /
User-agent: CCBot
Allow: /
Copy-paste ready: These are the exact robots.txt directives for each strategy. However, remember that ChatGPT-User compliance is no longer guaranteed as of December 2025.
After implementation, monitor your server logs to validate compliance. Not all bots reliably honor directives, and policies continue to evolve.
The NAV43 AI Crawler Decision Framework
Most guidance on AI crawlers stops at “it depends.” That’s not helpful when you’re trying to make actual decisions. Here’s the framework we use with clients at NAV43 to determine exactly which crawlers to allow or block.
Step 1: Assess Content Value
Ask: Is your content competitively differentiated?
- If you publish commodity content (generic how-tos, basic information), the risk of training AI models on it is lower – the information is already widely available
- If you publish proprietary research, unique methodologies, or differentiated insights, stricter controls are warranted
Score your content: Commodity (1) – Differentiated (3) – Proprietary (5)
Step 2: Define AI Visibility Goals
Ask: Do you want to be cited in AI-generated answers?
- If AI visibility is a strategic priority (and it should be for most B2B brands), retrieval crawlers must be allowed
- If you’re focused purely on traditional search and don’t care about AI citations, blocking is simpler
Score your goals: Don’t care (1) – Nice to have (3) – Strategic priority (5)
Step 3: Calculate Infrastructure Impact
Use server logs to measure:
– AI crawler request volume (monthly)
– Bandwidth consumed by AI crawlers
– Server response time impact during heavy crawl periods
Compare against referral traffic from AI platforms. If you’re spending $500/month in server costs serving AI crawlers that send $0 in traffic value, that’s a problem.
Step 4: Evaluate Training Sensitivity
Ask: Is your content being used to train tools that compete with your business?
- If you’re a research firm, and AI tools could replace your reports, training sensitivity is high
- If you’re an e-commerce brand and AI tools help users discover products, training sensitivity is lower
Step 5: Implement Segmented Access
Based on your scores, configure robots.txt to allow/block by crawler category – not blanket allow/deny. This is where most teams go wrong. They treat AI crawlers as a monolith rather than recognizing the different implications of training, retrieval, and user action.
Decision Matrix
| Content Type | Business Goal | Recommended Configuration |
|---|---|---|
| Commodity | Traffic | Allow all crawlers |
| Commodity | Brand awareness | Block training, allow retrieval |
| Differentiated | Traffic | Block training, allow retrieval |
| Differentiated | Brand awareness | Block training, allow retrieval |
| Proprietary | IP Protection | Block all AI crawlers |
| Proprietary | Brand awareness | Block training, allow retrieval with monitoring |
The NAV43 AI Crawler Audit Checklist
- [ ] Identify all AI crawlers in server logs (user-agent analysis)
- [ ] Categorize each by purpose (training/retrieval/user-action)
- [ ] Calculate crawl-to-refer ratio for each AI platform
- [ ] Assess the infrastructure cost of AI crawler traffic
- [ ] Score content value (commodity to proprietary)
- [ ] Define AI visibility goals
- [ ] Map current robots.txt configuration against business goals
- [ ] Document gaps between the current config and optimal config
- [ ] Implement segmented access by crawler category
- [ ] Set up ongoing monitoring for crawler activity changes
This framework aligns directly with our broader approach to AI SEO content strategy.
Server Log Analysis: How to Identify and Measure AI Crawler Traffic
Without server log analysis, you’re flying blind. You can’t measure the impact of AI crawlers, validate robots.txt compliance, or make data-driven decisions about crawler access. Here’s how to actually do this.
Where to Find Crawler Data
- Server access logs: The primary source – usually located at
/var/log/apache2/access.logor/var/log/nginx/access.log - CDN analytics: Cloudflare, Akamai, and Fastly all provide bot analytics dashboards
- Google Search Console: Limited crawler data, primarily for Googlebot
- Third-party tools: Semrush, Screaming Frog Log File Analyzer, Botify
User-Agent Patterns for AI Crawlers
Here are the exact user-agent strings to look for:
GPTBot: "GPTBot"
OAI-SearchBot: "OAI-SearchBot"
ChatGPT-User: "ChatGPT-User"
ClaudeBot: "ClaudeBot" or "anthropic-ai"
PerplexityBot: "PerplexityBot"
Bytespider: "Bytespider"
CCBot: "CCBot"
Amazonbot: "Amazonbot"
Google-Extended: Identified via Google robots.txt meta tag, not user-agent
Log Analysis Commands
For Linux/Unix systems, here’s how to extract AI crawler traffic:
# Count total requests by each AI crawler
grep -E "GPTBot|ClaudeBot|PerplexityBot|OAI-SearchBot|ChatGPT-User|Bytespider|CCBot|Amazonbot" access.log | awk '{print $14}' | sort | uniq -c | sort -rn
# List pages most crawled by GPTBot
grep "GPTBot" access.log | awk '{print $7}' | sort | uniq -c | sort -rn | head -20
# Calculate daily request volume from AI crawlers
grep -E "GPTBot|ClaudeBot|PerplexityBot" access.log | awk '{print $4}' | cut -d: -f1 | uniq -c
Metrics to Track
| Metric | What It Tells You |
|---|---|
| Total requests by crawler | Volume of AI crawler activity |
| Pages most frequently crawled | What content AI systems want |
| Crawl-to-refer ratio | Value exchange (requests vs referral traffic) |
| Response time during crawls | Infrastructure impact |
| Bandwidth consumed | Cost of serving AI crawlers |
| Compliance rate | Whether crawlers honor robots.txt |
AI crawlers account for 4.2% of all HTML page requests excluding Googlebot (Cloudflare, 2025). If your numbers are significantly higher, you may be a target for aggressive AI scraping.
We now run this analysis for every technical SEO audit. The data almost always surprises clients – they had no idea how much of their server capacity was going to AI crawlers sending zero traffic back.
The 30% Rule for AI: What It Actually Means
You may have heard references to “the 30% rule for AI.” Let me clarify: this “rule” has no single authoritative definition and is interpreted in multiple ways in the industry.
Interpretation 1: Content Creation
30% AI-generated content, 70% human-created content. This interpretation frames the rule as a quality guideline for maintaining E-E-A-T signals. The idea is that AI should assist, not dominate, your content creation process.
Interpretation 2: Workflow Automation
70% AI automation, 30% human oversight. This frames the rule as an efficiency guideline for content operations – let AI handle the bulk of repetitive tasks, but ensure human judgment remains in the loop.
NAV43’s Position
For SEO purposes, the content interpretation is more relevant. Google’s helpful content guidelines don’t specify a percentage, but they emphasize human oversight, expertise, and value-add. The question isn’t “how much AI?” but “does AI augment human expertise or replace it?”
The most effective approach we’ve seen with clients is using AI for:
– Research acceleration
– First draft generation
– Optimization suggestions
– Formatting and structure
While ensuring humans provide:
– Original insights and expertise
– Brand voice and perspective
– Fact-checking and validation
– Strategic direction
There’s no magic percentage. Focus on whether AI is augmenting human expertise or replacing it.
For a deeper dive into effective AI content workflows, see our guide on AI content creation workflows that scale quality.
Common Pitfalls: What Technical SEO Teams Get Wrong About AI Crawlers
After auditing crawler configurations for dozens of enterprise and e-commerce clients, we see the same mistakes repeatedly. Here’s what to avoid.
Pitfall 1: Treating All AI Crawlers the Same
Blanket blocking loses citation visibility. Blanket allowing train competitors to access your data. The nuance matters – training, retrieval, and user-action crawlers have different implications that require different responses.
Pitfall 2: Ignoring the December 2025 Policy Changes
ChatGPT-User no longer commits to honoring robots.txt. If your AI crawler strategy was set before December 2025, it’s likely out of date and potentially ineffective.
Pitfall 3: Assuming Robots.txt Blocking Prevents AI Citations
Data shows that 75% of blocked sites still get cited in AI-generated answers. Your content may be cached, available through third-party sources, or accessed through partnership arrangements you’re unaware of. Robots.txt is not a complete solution.
Pitfall 4: Not Monitoring Server Logs
Without log analysis, you can’t measure AI crawler impact or validate whether your robots.txt directives are actually being honored. Flying blind isn’t a strategy.
Pitfall 5: Forgetting JavaScript Rendering
AI crawlers can’t execute JavaScript. If your key content is client-side-rendered, AI systems can’t see it, regardless of your robots.txt configuration. This is a fundamental visibility problem that requires technical intervention.
Pitfall 6: Ignoring the Crawl-to-Refer Ratio
Allowing crawlers that take content but send no traffic back is a pure infrastructure cost with no ROI. Measure the ratio for each AI platform hitting your site and factor this into your access decisions.
Pitfall 7: No Structured Data for AI Systems
AI crawlers rely heavily on structured data (schema markup) to understand content context. Missing schema means missed citation opportunities. If you’re not implementing structured data for GEO, you’re leaving AI visibility on the table.
We see at least three of these pitfalls in every technical SEO audit we run. The most common? Treating AI crawlers as a monolith instead of segmenting by purpose.
Preparing for 2026 and Beyond: The AI Crawler Landscape Is Shifting
The trajectory is unmistakable. Gartner predicts traditional search engine volume will drop 25% by 2026 due to AI chatbots and virtual agents (Gartner, 2024). AI Overviews now appear in 25.11% of Google searches, up from 13.14% in March 2025 (Conductor, 2026).
What’s Coming
Increased user-action crawling: The 15x growth in user-triggered AI browsing in 2025 (Cloudflare) is just the beginning. As AI assistants become more capable of real-time web access, this category will dominate.
Erosion of robots.txt as a control mechanism: The December 2025 ChatGPT-User policy shift is a harbinger. Expect other platforms to follow, especially for user-triggered requests.
Multimodal crawling: AI systems are increasingly processing images, video, and audio content – not just text. Your visual assets may become training data.
Knowledge graph integration: AI systems increasingly rely on structured entity data. Brands that optimize for knowledge graphs will have compounding advantages in AI visibility.
Strategic Recommendations for Technical SEO Teams
- Implement server-side monitoring now. If you’re not tracking AI crawler activity, you’re making decisions without data.
- Segment your crawler access strategy by content type. Your proprietary research deserves different treatment from your general marketing content.
- Invest in server-side rendering for critical content. The JavaScript visibility gap is a growing liability as AI systems become more important for discovery.
- Build structured data as a priority, not an afterthought. Schema markup is the bridge between your content and AI comprehension.
- Accept that some control is illusory. Between cached content, third-party sources, and eroding compliance guarantees, your content will be in AI systems whether you like it or not. Strategy should focus on maximizing benefit while minimizing cost – not on achieving perfect control.
The shift from traditional search to AI-assisted discovery isn’t coming – it’s here. Technical SEO teams that adapt their crawler management strategies now will be positioned to thrive. Those that don’t will watch their infrastructure costs rise while their visibility in AI-generated answers declines.
For a comprehensive view of how AI is reshaping search optimization, see our full guide on AI SEO in 2025.
Final Thoughts: Strategy Over Control
The web was built on a simple bargain: crawlers index your content, search engines send you traffic. AI crawlers have broken that bargain. They take more, send less, and increasingly don’t feel obligated to ask permission. The 70,900:1 crawl-to-refer ratio isn’t a data point — it’s a verdict on the current value exchange between publishers and AI systems.
But the answer isn’t panic, and it isn’t blanket blocking. The technical SEO teams that will win in this environment are the ones that stop treating AI crawlers as a monolith and start making deliberate, segmented decisions: protect what’s proprietary, allow what builds visibility, and measure everything in between. The framework exists. The robots.txt configurations are straightforward. The server log analysis is doable. What’s missing for most teams is simply the decision to treat this as a strategic priority rather than a maintenance task.
The shift from search-first to AI-assisted discovery is not a future problem. It’s the current reality for any site where 40–60% of your prospective buyers are already using AI systems for research. The question is no longer whether AI crawlers matter to your business. It’s whether your crawler strategy reflects that they do.
